
期刊好文 | 整体效度观下语言测试四种效度验证模式: 解读、评价与启示(文/罗凯洲)
2020-03-06
▶ 摘要
本文旨在理清人们对整体效度观下语言测试四种效度验证模式的争议。首先,分析了整体效度观的核心思想;然后,解读受其影响而诞生的四种效度验证模式;随后,从效度本质、信效度关系、效度证据呈现三方面,对四种模式进行评价;最后,讨论效度模式为验证研究带来的启示。本文认为在四种效度验证模式中,TUM与SCF模式仍停留在分类效度观时期,IUA与AUA模式更符合整体效度观思想,即认为效度是成绩解释与使用合理性程度的属性,信度是效度必要不充分条件,效度证据呈现为“证伪”服务。效度验证模式也提醒从业人员应规范使用效度术语,分清测试利益攸关者责任并打通测试设计与效度验证的壁垒。
▶ 1.引言
效度是教育与心理测量领域最引人注目的议题,其重要性在语言测试学科也不例外。不同学者对效度的定义不尽相同,所采用的效度验证模式也各有差异,但人们普遍认为效度是一种表示程度的属性,收集并整合证据用以评价属性程度的过程就是效度验证。效度的发展大致历经两个时期:20世纪50年代至80年代后期的分类效度观时期和20世纪70年代中后期至今的整体效度观时期。其实,无论效度概念如何演变,只有将其转化为可操作的效度验证模式后才有真正意义和价值(O’Sullivan & Weir 2011:26)。所谓效度验证模式是指导效度验证过程的系统化参照方式 。
分类效度观时期,效度被视为测试质量的程度属性,教育与心理测量领域没有统一的验证模式,证据收集近似零敲碎打,呈现方式好像结果罗列。语言测试学科在很长一段时间内也效仿了这种做法。整体效度观时期,效度验证的对象不再是测试自身,而是有关成绩解释与使用合理性的一系列推断(主张)。受其影响,语言测试学科大致出现了四种效度验证模式。
然而,由于人们对整体效度观的理解存在差异,而效度验证模式构成也颇为复杂,如何选择和运用恰当的模式成了一道难题。以往虽有个别研究论及效度概念的演变、效度模式的构成、效度验证的重要性(李清华 2006;徐启龙 2012;韩宝成、罗凯洲 2013;Chapelle & Voss 2014),而在整体效度观视角下,解读并评价四种效度模式的研究仍不多见。本文通过分析教育与心理测量领域的整体效度观,解读在整体效度观下诞生的四种效度模式,从效度本质、信度与效度关系及效度证据呈现三方面,对四种模式进行评价,讨论效度模式为效度验证研究带来的启示。
▶ 2.整体效度观
20世纪70年代中后期,已有学者(Tenopyr 1977) 提出采用整体视角看待效度,改进以往零散的效度验证研究。Messick(1989:13) 则明确提出“效度是一个整体概念,是实证证据和理论依据对测试成绩解释与使用合理性的支持程度”。上述定义意味着效度本质已发生变化,它不再是测试质量的程度属性,而是测试成绩解释与使用合理性的程度属性。所谓成绩解释与使用的合理性程度实际上都是“推断”,推断好似“假设”,因此需要验证。按照Messick的本意,效度验证的对象正是这些“推断(主张)”,而不是测试本身,他曾用“多面效度框架”(facets of validity)来阐述“一元多维”的整体效度思想(Messick 1989:20)。该框架特别强调了测试成绩解释的价值内涵以及成绩使用所带来的社会后果,由此也引发语言测试学科的反拨作用研究。
整体效度观的提出,对教育与心理测量领域产生了深远影响。AERA et al. (1999,2014) 依据 Messick 整体效度观思想对这一领域的权威标准《教育与心理测验标准 》(Standards for Educational and Psychological Testing)(简称《标准》) 中的效度内容进行了修订。然而,整体效度观指导的效度验证被视为“永无止境的过程”(Cronbach 1989:151)。效度验证“何处开始、怎样进行、何时结束”对从业人员不具备操作性。由于Messick本人并未提出具体的效度验证模式,使得效度“理论”与“实践”严重脱节。如何整合与呈现效度证据,使效度验证变成一个有始有终的过程,《标准》也未给出明确建议,从业人员期待出现能指导效度验证实践的模式,这一需求在语言测试学科尤为突出。
▶ 3.对四种效度验证模式的解读
受整体效度观影响,语言测试学科大致出现了四种效度验证模式:Bachman & Palmer(1996)提出的“测试有用性模式”(Test Usefulness Model,简 称 TUM)、Weir(2005)提出的“社会认知模式”(Socio-Cognitive Framework,简称SCF)、Kane(1992,2006,2013)提出的“解释/使用论证模式”(Interpretation/Use Argument,简称 IUA) 以及Bachman(2003)、Bachman & Palmer (2010)提出的“测试使用论证模式” (Assessment Use Argument,简称 AUA)。下文将逐一解读四种模式的构成逻辑及模式的应用。
3.1 测试有用性模式
最先把整体效度观引入语言测试学科的是Lyle Bachman,他率先讨论了Messick“多面效度框架”在语言测试中应用的可能性(Bachman 1990)。为解决Messick遗留的效度实践问题,Bachman & Palmer(1996)提出了 “测试有用性模式” (TUM)(见图 1),用以指导语言测试的效度验证。该模式由以下表示测试质量的要素构成:

TUM提出后的十余年间,逐渐成为指导语言测试效度验证的重要模式。一些测试质量评价项目(Spence-Brown 2001)就采用了这一模式指导相关研究。部分语言测评素养的教材(Stoynoff & Chapelle 2005)也采用上述模式指导教师进行测试评价。TUM模式使语言测试学科告别以往零敲碎打式的效度验证方式,使从业人员认识到“构念效度”、“影响力”(测试后果)的重要性,从只关注传统的信度指标,转而关注语言测试的核心问题——构念如何界定、构念效度如何验证以及测试的反拨作用等。
3.2 社会认知模式
同受整体效度观的影响,Weir在2005年的专著《语言测试与效度验证》(Language Testing and Validation)中, 提出“社会认知模式”(SCF)(见图2)。O'Sullivan & Weir(2011:20)认为SCF是第一个把语言使用的社会、认知与评分维度系统融入测试效度验证的模式。
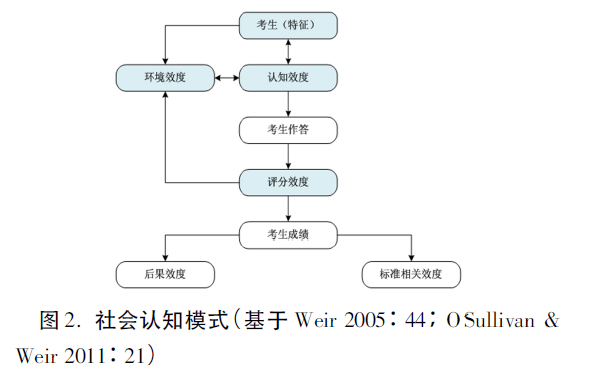
当前,SCF的应用研究大都集中在英国。例如,剑桥五级英语考试就采用了SCF进行效度验证,并以四项语言技能为纲,形成了关于效度验证的若干专论。普思英语考试(Aptis)也遵照SCF进行设计和效度研究(O'Sullivan 2015:6)。不少测试方向博士毕业论文的理论框架采用了SCF,论文作者大都毕业于Weir就职的贝特福德大学(Saville 2009)。
3.3 解释/使用论证模式
Kane(1992,2006,2013)在Messick整体效度观指导下,以哲学家Toulmin(1958)的实用论证模型为依据,提出了基于论证的效度验证模式(argument-based approach to validation)。Kane(2006)为第四版《教育测量》( Educational Measurement)撰写的“效度验证”章节中对这一模式进行了详细说明。该模式包含两步论证。第一步是“解释/ 使用论证”(IUA),目的是搭建一个环环相扣的推理链,每次推理都有待论证,好似构建一个“理论框架”(见图3)。第二步是“效度论证”(validity argument),就是对 “理论框架”的检验过程。
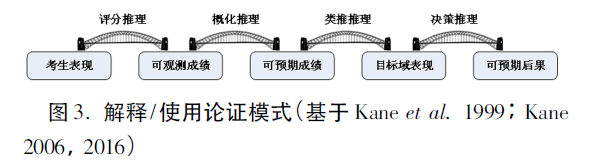
例如,由“考生表现”到“可观测成绩”(即考试分数或等级)的“评分推理”中,考生表现是“事实”,可观测成绩是“主张”,经论证之后,主张即成“结论”,又可作为下一推理阶段的事实使用。“事实→结论/ 主张”的实用论证模型认为推理过程需要有“理据”来支撑,理据自身必须有“证据”加以证明。然而,理据往往不具备百分百的确定性,可能存在“例外”,即“反驳情况”,所以被推导出的结论(主张)通常会有“限定条件”加以约束。当“概化推理”、“类推推理”以及“决策推理”中的各段论证逐一构建完毕后,IUA才算构建完成。值得注意的是,Kane的IUA模式最初并非专为语言测试提出,但这一模式在语言测试学科得到充分应用,或许和Kane担任美国教育考试服务中心(ETS)的效度理论研究首席专家有关。ETS历时近10年,运用Kane的模式对新托福考试进行了效度验证,收效良好,这也是大规模高利害测试首次采用基于论证的效度验证模式进行的效度研究(Chapelle et al.2008)。一些效度验证研究的博士毕业论文亦采用了IUA模式(Aryadoust 2013;Drackert 2015)。
3.4 测试使用论证模式
IUA模式目前更适合于专业考试机构进行效度验证,因为如何构建IUA推理链确实需要专业背景。虽然 Kane(2016:79)曾提醒在构建IUA时,应该尽量清晰、连贯、合理,既不能“轻描淡写”(understate),也不能“小题大做” (overstate),但只懂得一点测评常识的人仍难驾驭。Bachman针对上述现实需求,于2003年提出了专门针对语言测试的“测试使用论证模式”(AUA)(见图 4)。AUA借鉴并吸收了Messick(1989)的整体效度思想、Kane(2006)的基于论证的效度验证模式以及 Toulmin(1958/2003)的实用推理论证模型,最终在《语言测评实践》(Language Assessment in Practice)(Bachman & Palmer 2010)一书中得到系统论述。

AUA模式的论证逻辑与IUA近似,此处不再赘述。AUA已被用在不少效度验证研究中。例如,Bachman指导的部分博士论文应用了AUA作为研究框架(Wang 2010), Schmidgall(2017)使用AUA为托业考试构建效度验证框架,范劲松(2018)运用AUA作为指导测试标准制定与效度检验的理论框架。虽然AUA指导的大规模高利害测试开发并不多见,但在低利害的语言课堂评价情境中,也显示出了强大的实践价值(Bachman & Damböck 2017)。
综上,四种模式出现时间虽有先后,但彼此间并非“升级换代”、更不是“范式转换”关系。例如,AUA并非在TUM的基础上发展而来( Bachman & Palmer 2010: vii)。因为,TUM对整体效度观理解并不彻底,仍沿用了分类效度观中的部分概念,使得效度理论与实践错位。大概在Bachman首次提出AUA模式的同一时期,Weir(2005)提出 SCF模式,这一模式看似比TUM包含的要素更为丰富,但要素间有何逻辑关联,为何要沿用分类效度观的效度类别概念,Weir并未阐释清楚。
▶ 4.对四种效度验证模式的评价
传统认为,效度、信度及其相关证据是效度验证研究中最核心的议题。如何看待效度的本质,如何处理信度与效度的关系,以及如何收集与呈现证据是区别分类效度观与整体效度观的关键因素。下文将从这三方面评价四种模式的共性与差异。
4.1 对效度本质的认识
整体效度观下,所谓“测试的效度”被视为“不准确的措辞”,因为需要验证的不是测量工具自身,而是关于如何解释与使用成绩的一系列推断(主张)( AERA et al. 2014:11)。四种效度模式均声明是整体效度观指导下的模式,但他们对效度本质的认识却有天壤之别(表1)。
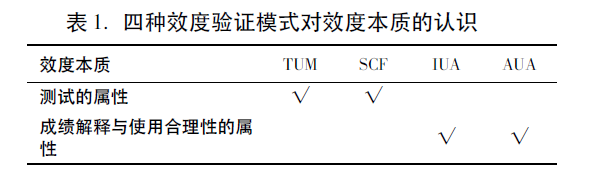
TUM与SCF均把效度看作测试自身的属性、效度验证的对象就是测试质量(Bachman & Palmer 1996:19;Weir 2005:15),这与当今教育与心理测量领域的主流思想相悖。此外,这两种模式均使用了信度、构念效度(认知效度)、后果效度(影响力)、标准相关效度等分类效度观下的概念。严格意义上,TUM与SCF不应被视作整体效度观的验证模式。IUA与AUA把效度看作“测试成绩的解释和使用的合理性”,而效度验证对象是表示这些合理性程度的主张,更符合效度整体观对效度本质的认识。
《教育测量》与《标准》等权威文献,均把效度作为开篇,其重要性可见一斑。效度虽然重要,却是教育与心理测量词库中最复杂的词汇(Newton & Shaw 2016),在很长一段时间内,效度被当作测试质量的代名词,人们常把“测试的效度”和“测试的质量”混为一谈。四种效度模式对效度一词的使用存在差异,究其原因,是由于对效度本质的认识所致。
4.2 对信度与效度关系的认识
广义上看,信度泛指测试成绩的“一致性”,可由经典测量理论下的信度系数、概化理论下的概化系数、项目反应理论下的信息函数等参数来解释;狭义上看,信度专指经典测量理论下的信度系数(AERA et al. 2014:33)。几十年来,信度概念并未发生太大变化,真正让从业者感觉困惑的是信度与效度的关系。四种效度验证模式在处理效度与信度关系时采用了不同策略(表2)。
分类效度观下,信度与效度同时被当作衡量测试质量的重要指标,各自都有专门的评价(或计算)方式(Alderson & Banerjee 2002)。整体效度观下,信度被视作效度的前提,即“必要不充分条件” (necessary but not sufficient condition) (Kane 2013)。TUM直接沿用了分类效度时期的观点,把效度、信度同时当作测试质量的两个重要方面。SCF则将信度(即评分效度)当作整体效度的一个子类, 这相比TUM已有进步。整体效度观下的信度虽仍旧是评价成绩准确性的重要维度,但已被降格为效度证据来源的一个方面。IUA与AUA对此均有体现。IUA中的信度由“评分推理”与“概化推理”过程表示,AUA则彻底放弃了信度术语,取而代之的是用以形容成绩质量主张的各类“属性”。两种模式表示信度的措辞不同,均将信度看作效度的前提条件,这更加符合整体效度观理念。
整体效度观下,如同不存在所谓“测试的效度”一样, 信度也不是测试的信度,应该是“测试成绩的信度”。信度高,效度高未必高,因为成绩一致性高,并不意味着成绩解读与使用的合理程度高。

4.3 对效度证据的认识
效度证据通常包括测试内容证据、作答过程证据、测试结构证据、测试后果证据以及成绩与其他变量的关联证据等(AERA et al. 1999,2014)。证据类别不同,收集方法各异。既有逻辑分析方法,如专家判断、有声思维、公文收集等获得的质的证据;也有实证研究方法,如使用经典测验理论、项目反应理论、因子分析方法等得到的量的证据;还有依靠实验研究方法,如运用眼动、脑电实验所取得 的作答过程证据等。分类效度观指导的证据收集与呈现倾向于“证实”(verificationism),而整体效度观则倾向于 “证伪”(falsificationism)。如果单看证据类别和收集方法,四种效度模式并无本质区别。然而,在证据呈现的理念上却存在较大差异(表3)。
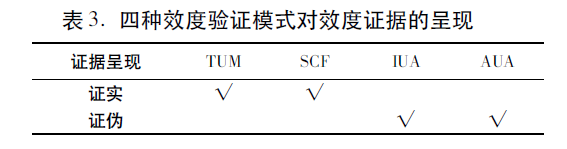
TUM指导的效度验证,要按照测试有用性的六项要素收集并呈现证据。为方便从业人员进行相对规范的效度验证,Bachman & Palmer(1996)提出了42个问题指导这一过程。Weir(2005)也建议依照SCF各效度类别中的具体内容收集和呈现各类证据。Fulcher(2015:117-119)把上述方式比喻成效度验证的“核对清单”(checklist),这种方式很可能“掩盖”效度验证中的真问题,因为测试设计者总能“挑选”一些有利证据来“证实”效度。TUM突出了直观、易懂的特点,却牺牲了理论的连贯性(McNamara 2003),在一定程度上甚至错误地解读了Messick整体效度观。
IUA和AUA同属基于论证的效度验证模式。这类模式强调没有列出的推理环节及主张就无须论证 Kane(2016:64)。换言之,从业人员只需要收集与既定推断(主张)密切相关的证据即可,无须像TUM或SCF那样,把与测试质量、成绩解释和使用相关的证据悉数列出。因为,证据在IUA或AUA中并不是为了“证实”效度,而是为了验证IUA或AUA中“可证伪的”推断(主张),帮助从业人员发现问题。
在整体效度观下出现的四种模式虽然各自表述不同,但都涉及了构念效度(认知效度)、信度等相关内容。然而,从对效度本质的理解来看,TUM与SCF仍认为效度验证的对象是测试自身,而IUA与AUA则认为效度验证的对象是表示成绩解释与使用合理性程度的一系类推断(主张)。从对信度与效度关系的认识来看,TUM认为信度与效度同为测试的质量属性,SCF则认为信度属于效度,IUA与AUA认为信度是效度的必要但不充分条件。从对效度证据的观念来看,TUM与SCF对证据呈现的方式倾向于“证实”,而IUA与AUA则倾向于“证伪”。
总体看来,TUM与SCF的观念仍停留在分类效度观时期,IUA与AUA才符合整体效度观思想。SCF同TUM一样,虽在整体效度观下诞生,但只能算“过渡产物”。四种效度模式可能还会并存,但我们有理由相信IUA与AUA更具优势。因为,IUA与AUA使效度验证的逻辑发生了变化,一定程度上解决了“何处开始、怎样进行、何时 结束”的难题。构建IUA或AUA就是“起点”,论证IUA或AUA就是“过程”,论证完毕的 IUA或AUA就是“终点”。此外,IUA与AUA的理论依据都基于Toulmin的实用论证模型。实用论证模型虽然把反驳的举证责任“转嫁”给了挑战主张的人(Kane 2013),类似司法领域的“疑罪从无”,但并不意味反驳(主张)在构建论证时可有可无。IUA与AUA都认为反驳也是基于论证的效度验证过程中的重要因素,能起到警示作用。此外,IUA与AUA均对推理过程持开放态度,认为推理链应有较强的灵活性, 从业人员可依照现实条件对推理论证链中的主张适当增删。
